 Prometheus: Alerty
Prometheus: Alerty
Jak działają alerty Prometheus i jak je skonfigurować
👋 Witamy w dokumentacji Stackhero!
Stackhero oferuje gotowe do użycia rozwiązanie Prometheus cloud, które zapewnia wiele korzyści, w tym:
Alert Managerw zestawie do wysyłania alertów doSlack,Mattermost,PagerDuty, itp.- Dedykowany serwer e-mail do wysyłania nieograniczonych alertów e-mail.
Blackboxdo sondowaniaHTTP,ICMP,TCPi więcej.- Łatwa konfiguracja z edytorem plików konfiguracyjnych online.
- Bezproblemowe aktualizacje za pomocą jednego kliknięcia.
- Optymalna wydajność i solidne bezpieczeństwo dzięki prywatnej i dedykowanej VM.
Oszczędzaj czas i upraszczaj swoje życie: wystarczy 5 minut, aby wypróbować rozwiązanie Prometheus cloud hosting Stackhero!
Wprowadzenie do alertów Prometheus
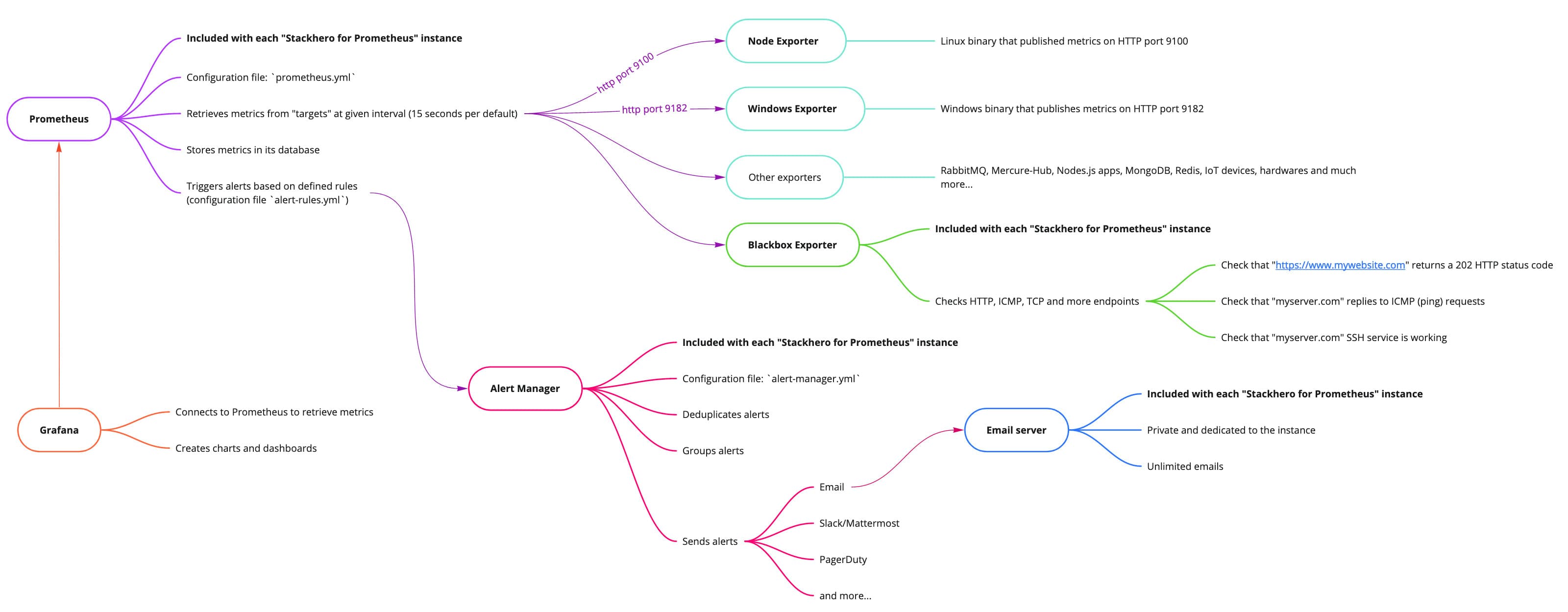
Prometheus może analizować Twoje metryki i wyzwalać alerty na podstawie zdefiniowanych przez Ciebie reguł. Z Stackhero dla Prometheus alerty są przetwarzane w dwóch etapach. Najpierw oceniane są reguły alertów Prometheus, a następnie przejmuje Alert Manager.
Wszystko jest wstępnie zainstalowane i skonfigurowane z Stackhero dla Prometheus, więc musisz wykonać minimalną konfigurację, taką jak dodanie swojego adresu e-mail, aby zacząć otrzymywać alerty.
 Ogólny widok Stackhero dla Prometheus
Ogólny widok Stackhero dla Prometheus
Wprowadzenie do reguł alertów Prometheus
Kiedy Prometheus pobiera metryki, ocenia je w odniesieniu do reguł określonych w pliku rules-alert.yml. Te reguły alertów definiują progi i okna czasowe dla wyzwalania alertów na podstawie zebranych metryk.
Na przykład, alert może zostać wyzwolony, jeśli użycie dysku przekroczy 80%. Dodatkowo, można ustawić reguły przewidujące przyszłe warunki i wysłać alert, jeśli szacuje się, że przestrzeń dyskowa zostanie całkowicie zapełniona w ciągu następnych 24 godzin.
Innym powszechnym przypadkiem użycia jest wykrywanie nietypowego zachowania. Na przykład, jeśli nastąpi nagły wzrost użycia przepustowości sieci, może zostać wyzwolony alert, aby pomóc w wykryciu potencjalnych ataków DDoS lub prób wycieku danych.
Reguły alertów Prometheus są bezpośrednio zawarte w serwerze Prometheus.
Wprowadzenie do Alert Manager
Alert Manager odbiera alerty wyzwolone przez reguły alertów Prometheus. Deduplikuje alerty, grupuje je, a następnie przesyła za pośrednictwem różnych kanałów powiadomień, takich jak e-mail, Slack, Mattermost, PagerDuty i inne. Jego plik konfiguracyjny to alert-manager.yml.
Na przykład, jeśli wystąpi spowolnienie serwera, reguły alertów Prometheus mogą wyzwolić oddzielne alerty dla zwiększonego obciążenia i użycia CPU. Alert Manager odbiera te alerty, grupuje je, ponieważ dotyczą tego samego serwera, i wysyła skonsolidowane powiadomienie do odpowiedniego odbiorcy lub zespołu na podstawie Twojej konfiguracji.
Jeśli spowolnienie będzie się utrzymywać, Prometheus będzie nadal wysyłać alerty, ale Alert Manager będzie tłumić duplikaty wiadomości przez określony czas, aby zapobiec zalewaniu zespołu redundantnymi alertami.
Możesz również wyciszyć lub całkowicie zablokować alerty, jeśli to konieczne. Po rozwiązaniu podstawowego problemu wysyłana jest wiadomość o odzyskaniu, aby powiadomić Twoje zespoły.
Ten przykład ilustruje typowy scenariusz, ale możesz w pełni dostosować konfigurację do swoich specyficznych wymagań.
ostrzeżenie
Alert Managernie jest domyślnie dołączony do Prometheus. Aby zaoszczędzić Twój czas i uprościć proces, zintegrowaliśmy i skonfigurowaliśmyAlert Managerw Stackhero dla Prometheus, abyś mógł wysyłać alerty w zaledwie kilka minut, z minimalnym wysiłkiem.
Konfigurowanie reguł alertów Prometheus
Możesz dostosować reguły alertów Prometheus, edytując plik rules-alert.yml. Aby to zrobić, uzyskaj dostęp do swojego panelu Stackhero, wybierz swoją usługę Prometheus i kliknij "Konfiguracja reguł alertów Prometheus".
Dodaliśmy już kilka domyślnych reguł alertów do Twojej instancji Stackhero dla Prometheus, więc zazwyczaj nie będziesz musiał modyfikować pliku rules-alert.yml, chyba że wymagana jest personalizacja.
Poniżej znajduje się przykład alertu, który wyzwala się, jeśli użycie dysku przekroczy 90%:
- alert: "HostOutOfDiskSpace"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)"
value: "{{ $value }}"
Oto kolejny przykład, który przewiduje potencjalne zapełnienie przestrzeni dyskowej w ciągu następnych 24 godzin:
- alert: "HostDiskWillFillIn24Hours"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host disk will fill in 24 hours (instance {{ $labels.instance }})"
description: "Filesystem is predicted to run out of space within the next 24 hours at the current write rate"
value: "{{ $value }}"
Możesz znaleźć wiele dodatkowych przykładów reguł alertów na stronie Awesome Prometheus Alerts.
Konfigurowanie Alert Manager
Aby skonfigurować Alert Manager, edytuj plik alert-manager.yml. W swoim panelu Stackhero wybierz swoją usługę Prometheus, a następnie kliknij "Konfiguracja Alert Manager".
Poniżej przedstawiamy podstawy. Aby uzyskać więcej szczegółów, zapoznaj się z oficjalną dokumentacją.
Konfigurowanie Alert Manager: odbiorcy
Pierwszym krokiem jest skonfigurowanie receivers. Każdy receiver to zestaw integracji powiadomień (takich jak e-mail, Slack itp.) zidentyfikowany przez unikalną name.
Na przykład, możesz utworzyć odbiorcę o nazwie "critical_alert" dla powiadomień wyzwolonych przez alerty o krytycznej ważności. Alternatywnie, możesz utworzyć odbiorcę jak "devops_team", aby kierować alerty do swojego zespołu DevOps.
Ustawienie nazwy
receiverna "critical_alert" samo w sobie nie wyśle alertów. Powiązanie między alertami a odbiorcą jest dokonywane w konfiguracjiroutesopisanej poniżej.
Po zdefiniowaniu odbiorcy, będziesz musiał skonfigurować odpowiednie integracje powiadomień. Mogą to być e-maile, powiadomienia Slack/Mattermost, PagerDuty, Opsgenie, Webhook i inne.
Poniżej znajduje się przykład receiver o nazwie "critical_alert", który wysyła e-mail do dwóch użytkowników i wiadomość Slack do kanału #alerts:
receivers:
- name: "critical_alert"
# Wysyłanie krytycznych alertów przez e-mail
email_configs:
- send_resolved: true
to: "user@mycompany.com"
# Wysyłanie krytycznych alertów do Slack lub Mattermost
slack_configs:
- send_resolved: true
api_url: "<your Slack or Mattermost API URL>"
channel: "#alerts"
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"
Możesz zdefiniować wielu odbiorców do obsługi różnych typów alertów. Na przykład, możesz mieć jednego dla alertów krytycznych, innego dla alertów błędów i jeszcze innego dla innych typów alertów.
Instancje Stackhero dla Prometheus zawierają dedykowany i prywatny serwer e-mail, który pozwala na wysyłanie nieograniczonej liczby alertów e-mail bez dodatkowych kosztów.
Konfigurowanie Alert Manager: trasy
Po skonfigurowaniu odbiorców, musisz ustawić routes. Trasy informują Alert Manager, jak obsługiwać przychodzące alerty z Prometheus i gdzie je wysyłać (zazwyczaj do jednego z wcześniej skonfigurowanych odbiorców).
Poniżej znajduje się podstawowy przykład, który kieruje alerty o ważności "critical" do odbiorcy o nazwie "critical_alert":
route:
routes:
- match:
severity: "critical"
receiver: "critical_alert"
W pliku
alert-manager.ymldostarczonym z Twoją instancją Stackhero dla Prometheus wstępnie skonfigurowaliśmy niektóre trasy. Aby zacząć otrzymywać alerty, wystarczy zaktualizować sekcjeemail_configsi/lubslack_configsz Twoimi szczegółami powiadomień.