 Elasticsearch: Wtyczka Ingest Attachment
Elasticsearch: Wtyczka Ingest Attachment
Jak wyodrębnić dane z plików PPT, XLS i PDF do Elasticsearch
👋 Witamy w dokumentacji Stackhero!
Stackhero oferuje gotowe do użycia rozwiązanie Elasticsearch cloud, które zapewnia wiele korzyści, w tym:
- Optymalną wydajność i solidne zabezpieczenia dzięki prywatnej i dedykowanej VM.
- Dostosowywalną nazwę domeny zabezpieczoną wsparciem szyfrowania HTTPS.
Oszczędzaj czas i upraszczaj sobie życie: wystarczy 5 minut, aby wypróbować rozwiązanie Elasticsearch cloud hosting Stackhero!
Wtyczka Ingest Attachment analizuje i wyodrębnia metadane oraz tekst z różnych formatów plików, w tym prezentacji PowerPoint, dokumentów Excel i PDF. Wykorzystuje Apache Tika, potężną bibliotekę do ekstrakcji tekstu. Pełną listę obsługiwanych formatów można znaleźć na stronie Tika.
Ten przewodnik pomoże Ci rozpocząć pracę z wtyczką.
Dodaj wtyczkę do Elasticsearch
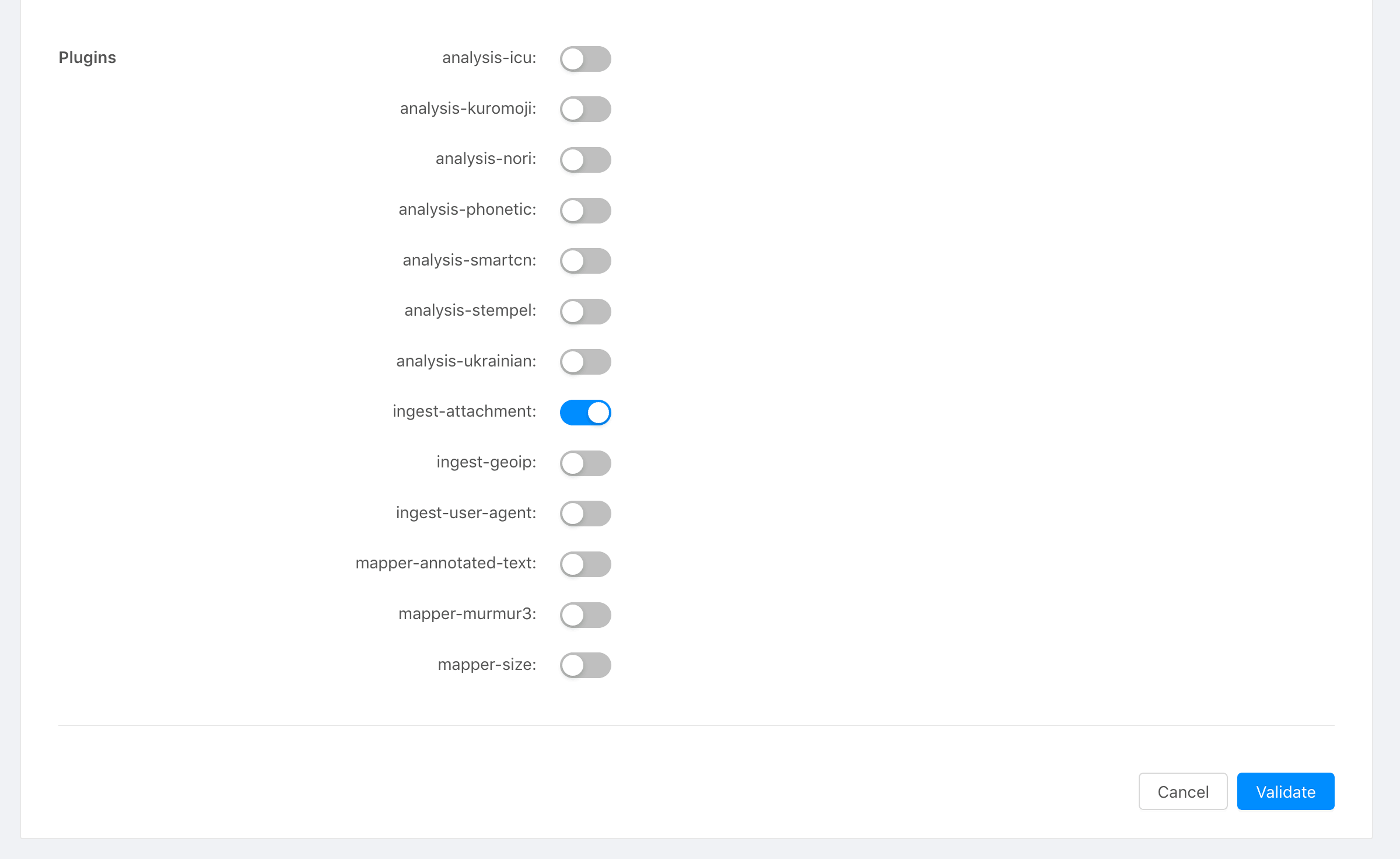
Najpierw włącz wtyczkę w konfiguracji Stackhero Elasticsearch:
- Przejdź do sekcji Elasticsearch na swoim pulpicie nawigacyjnym Stackhero.
- Wybierz wtyczkę
ingest-attachmentz dostępnych opcji.
 Pulpit nawigacyjny Stackhero
Pulpit nawigacyjny Stackhero
Zadeklaruj pipeline załączników
Następnie zadeklaruj pipeline załączników w Elasticsearch. W tym przykładzie zawartość, którą chcesz wyodrębnić, jest przechowywana w polu data:
PUT _ingest/pipeline/attachment
{
"description": "Wyodrębnij informacje o załączniku",
"processors": [
{
"attachment": {
"field": "data"
}
}
]
}
Zalecamy użycie "Dev Tools" w Kibana do prostego wykonania tej komendy przez kopiowanie/wklejanie.
 Narzędzia deweloperskie Kibana
Narzędzia deweloperskie Kibana
Dodaj dokument z załącznikiem
Teraz możesz zaindeksować dokument zawierający załącznik. Dokument powinien zawierać pole data, które przechowuje zawartość pliku zakodowaną w Base64. W tym przykładzie dokument to plik RTF zawierający zdanie "This is the content of an RTF file":
PUT my_index/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ=="
}
Pobierz dokument z zawartością załącznika
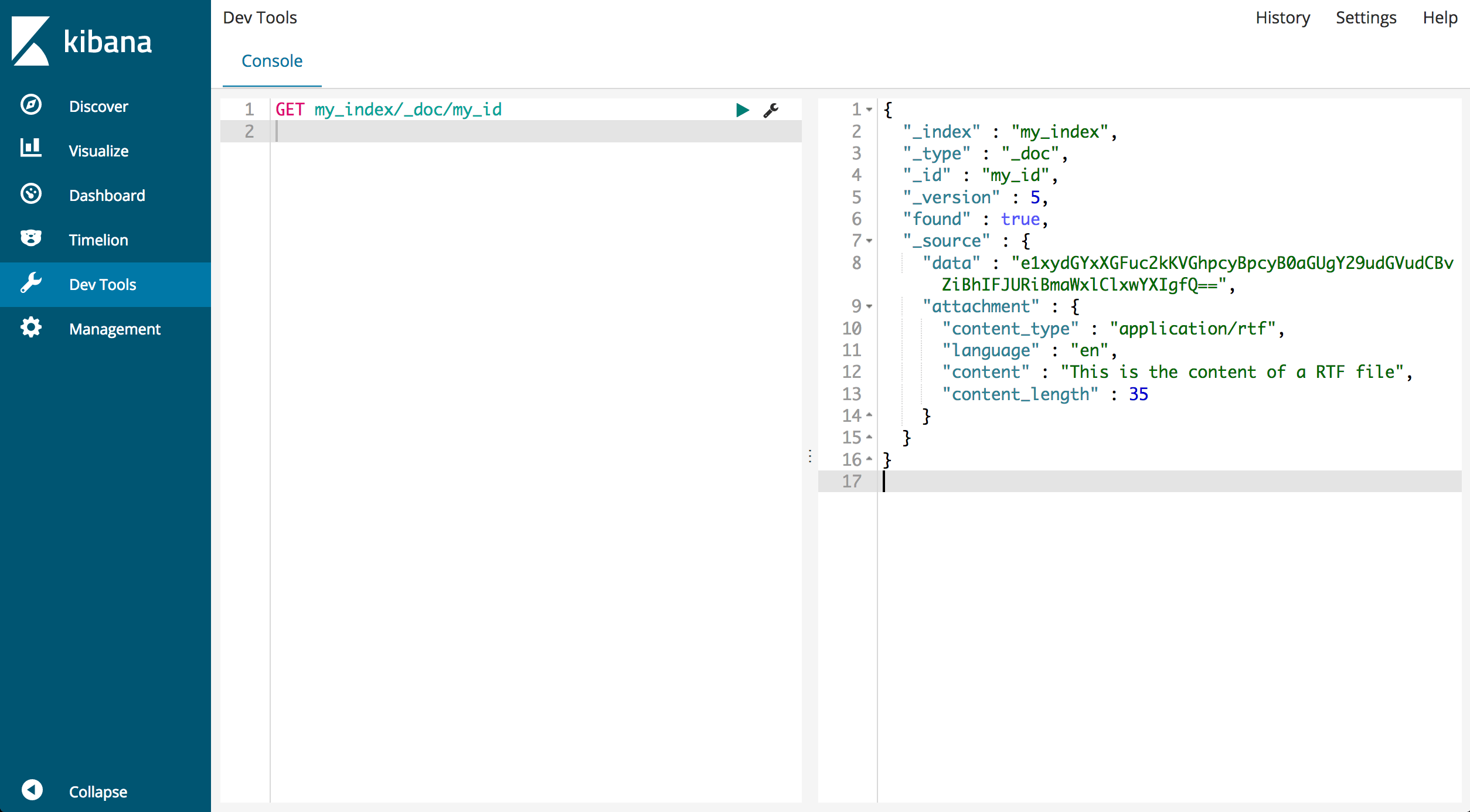
Aby zobaczyć przetworzony dokument, pobierz go używając jego ID:
GET my_index/_doc/my_id
Odpowiedź powinna wyglądać podobnie do poniższej:
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "my_id",
"_version" : 1,
"found" : true,
"_source" : {
"data" : "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ==",
"attachment" : {
"content_type" : "application/rtf",
"language" : "en",
"content" : "This is the content of a RTF file",
"content_length" : 35
}
}
}
Zauważ, że pole _source teraz zawiera zarówno oryginalne dane Base64, jak i wyodrębnione szczegóły załącznika, takie jak typ pliku i zawartość.
Wniosek
Wtyczka Ingest Attachment to potężne i przyjazne dla użytkownika narzędzie do wyodrębniania treści i metadanych z różnych formatów plików. Integruje się bezpośrednio z Elasticsearch, zapewniając płynne pobieranie danych. Aby uzyskać dodatkowe informacje, zapoznaj się z oficjalną dokumentacją.