 Prometheus: Alertas
Prometheus: Alertas
Como funcionam os alertas do Prometheus e como configurá-los
👋 Bem-vindo à documentação da Stackhero!
A Stackhero oferece uma solução Prometheus cloud pronta a usar que proporciona uma série de benefícios, incluindo:
Alert Managerincluído para enviar alertas paraSlack,Mattermost,PagerDuty, etc.- Servidor de email dedicado para enviar alertas de email ilimitados.
Blackboxpara sondarHTTP,ICMP,TCP, e mais.- Configuração fácil com editor de ficheiros de configuração online.
- Atualizações sem esforço com apenas um clique.
- Desempenho ótimo e segurança robusta alimentados por uma VM privada e dedicada.
Poupe tempo e simplifique a sua vida: leva apenas 5 minutos para experimentar a solução de hospedagem cloud Prometheus da Stackhero!
Introdução aos alertas do Prometheus
O Prometheus pode analisar as suas métricas e acionar alertas com base em regras que definir. Com o Stackhero para Prometheus, os alertas são processados em duas etapas. Primeiro, as regras de alerta do Prometheus são avaliadas e depois o Alert Manager assume.
Tudo está pré-instalado e configurado com o Stackhero para Prometheus, por isso só precisa de realizar uma configuração mínima, como adicionar o seu endereço de email, para começar a receber alertas.
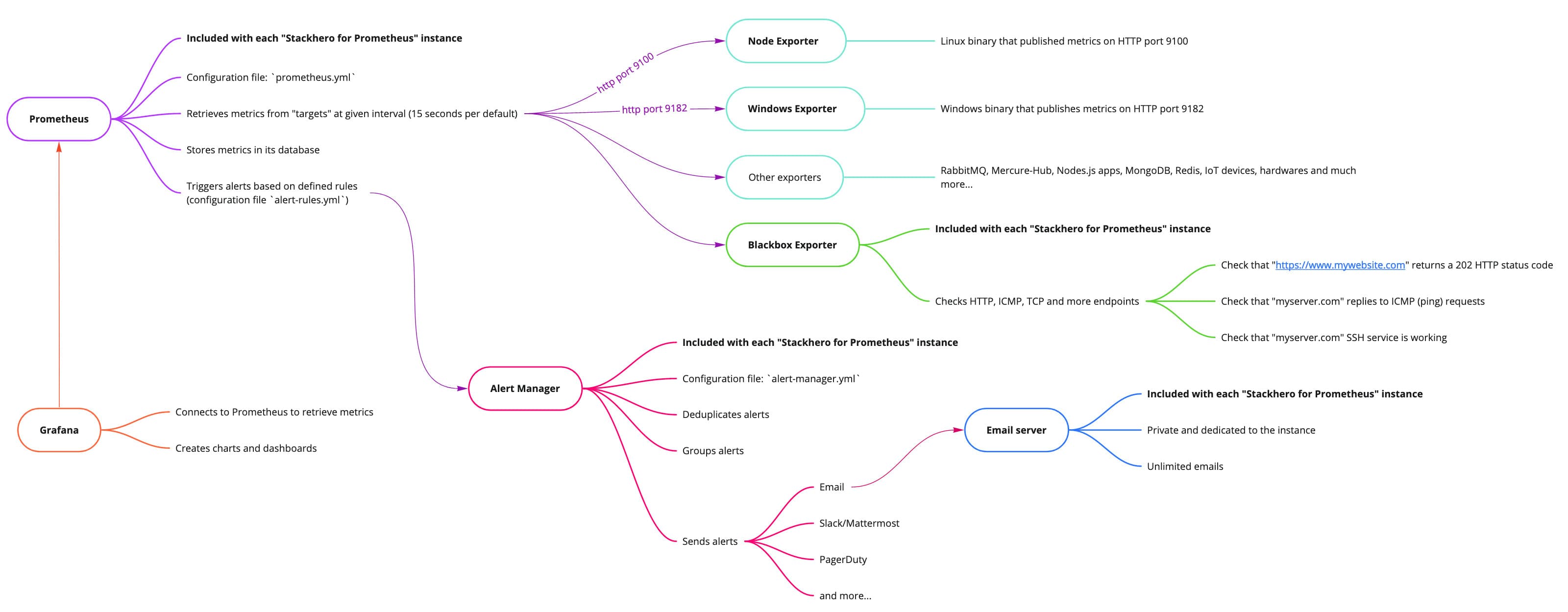 Visão geral do Stackhero para Prometheus
Visão geral do Stackhero para Prometheus
Introdução às regras de alerta do Prometheus
Quando o Prometheus recupera métricas, avalia-as em relação às regras especificadas no ficheiro rules-alert.yml. Estas regras de alerta definem limites e janelas de tempo para acionar alertas com base nas métricas recolhidas.
Por exemplo, um alerta pode ser acionado se a utilização do disco exceder 80%. Além disso, podem ser configuradas regras para prever condições futuras e enviar um alerta se estimar que o espaço em disco será completamente preenchido nas próximas 24 horas.
Outro caso de uso comum envolve a deteção de comportamento incomum. Por exemplo, se houver um aumento repentino no uso da largura de banda da rede, um alerta pode ser acionado para ajudar a detetar potenciais ataques de negação de serviço distribuído (DDoS) ou tentativas de exfiltração de dados.
As regras de alerta do Prometheus estão incluídas diretamente no servidor Prometheus.
Introdução ao Alert Manager
O Alert Manager recebe alertas que as regras de alerta do Prometheus acionaram. Ele desduplicará alertas, agrupa-os e depois encaminha-os através de vários canais de notificação, como email, Slack, Mattermost, PagerDuty, entre outros. O seu ficheiro de configuração é alert-manager.yml.
Por exemplo, se ocorrer uma desaceleração do servidor, as regras de alerta do Prometheus podem acionar alertas separados para carga aumentada e uso de CPU. O Alert Manager recebe esses alertas, agrupa-os pois estão relacionados ao mesmo servidor, e envia uma notificação consolidada ao destinatário ou equipa apropriada com base na sua configuração.
Se a desaceleração continuar, o Prometheus continuará a enviar alertas, mas o Alert Manager suprimirá mensagens duplicadas por um período especificado para evitar sobrecarregar a sua equipa com alertas redundantes.
Também pode silenciar ou inibir completamente alertas, se necessário. Uma vez resolvido o problema subjacente, uma mensagem de recuperação é enviada para notificar as suas equipas.
Este exemplo ilustra um cenário comum, mas pode personalizar totalmente a configuração para atender às suas necessidades específicas.
aviso O
Alert Managernão está incluído por padrão com o Prometheus. Para poupar tempo e simplificar o processo, integrámos e configurámos oAlert Managerno Stackhero para Prometheus para que possa enviar alertas em apenas alguns minutos, com um esforço mínimo.
Configuração das regras de alerta do Prometheus
Pode ajustar as regras de alerta do Prometheus editando o ficheiro rules-alert.yml. Para fazer isso, aceda ao seu painel Stackhero, selecione o seu serviço Prometheus e clique em "Configuração das regras de alerta do Prometheus".
Já adicionámos algumas regras de alerta padrão à sua instância Stackhero para Prometheus, por isso geralmente não precisará de modificar o ficheiro rules-alert.yml a menos que seja necessária personalização.
Abaixo está um exemplo de um alerta que é acionado se a utilização do disco exceder 90%:
- alert: "HostOutOfDiskSpace"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)"
value: "{{ $value }}"
Aqui está outro exemplo que prevê uma potencial saturação do espaço em disco nas próximas 24 horas:
- alert: "HostDiskWillFillIn24Hours"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host disk will fill in 24 hours (instance {{ $labels.instance }})"
description: "Filesystem is predicted to run out of space within the next 24 hours at the current write rate"
value: "{{ $value }}"
Pode encontrar muitos exemplos adicionais de regras de alerta no site Awesome Prometheus Alerts.
Configuração do Alert Manager
Para configurar o Alert Manager, edite o ficheiro alert-manager.yml. No seu painel Stackhero, selecione o seu serviço Prometheus e clique em "Configuração do Alert Manager".
Abaixo, apresentamos o básico. Para mais detalhes, consulte a documentação oficial.
Configuração do Alert Manager: os receivers
O primeiro passo é configurar os receivers. Cada receiver é um conjunto de integrações de notificação (como email, Slack, etc.) identificado por um name único.
Por exemplo, pode criar um receiver chamado "critical_alert" para notificações acionadas por alertas com gravidade crítica. Alternativamente, pode criar um receiver como "devops_team" para direcionar alertas para a sua equipa DevOps.
Definir um
receivercom o nome "critical_alert" sozinho não enviará alertas. A associação entre alertas e o receiver é feita na configuração dasroutesdescrita abaixo.
Uma vez definido um receiver, precisará configurar as integrações de notificação correspondentes. Estas podem incluir emails, notificações Slack/Mattermost, PagerDuty, Opsgenie, Webhook, entre outros.
Abaixo está um exemplo de um receiver chamado "critical_alert" que envia um email para dois utilizadores e uma mensagem Slack para o canal #alerts:
receivers:
- name: "critical_alert"
# Enviar alertas críticos por email
email_configs:
- send_resolved: true
to: "user@mycompany.com"
# Enviar alertas críticos para Slack ou Mattermost
slack_configs:
- send_resolved: true
api_url: "<your Slack or Mattermost API URL>"
channel: "#alerts"
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"
Pode definir múltiplos receivers para lidar com diferentes tipos de alertas. Por exemplo, pode ter um para alertas críticos, outro para alertas de erro, e outro para outros tipos de alertas.
As instâncias de Stackhero para Prometheus incluem um servidor de email dedicado e privado que lhe permite enviar um número ilimitado de alertas por email sem custo adicional.
Configuração do Alert Manager: as routes
Depois de configurar os seus receivers, precisa configurar as routes. As routes dizem ao Alert Manager como lidar com os alertas recebidos do Prometheus e para onde enviá-los (tipicamente para um dos seus receivers pré-configurados).
Abaixo está um exemplo básico que direciona alertas com uma gravidade de "critical" para o receiver chamado "critical_alert":
route:
routes:
- match:
severity: "critical"
receiver: "critical_alert"
Pré-configurámos algumas routes no ficheiro
alert-manager.ymlfornecido com a sua instância Stackhero para Prometheus. Para começar a receber alertas, basta atualizar as secçõesemail_configse/ouslack_configscom os seus detalhes de notificação.