 Elasticsearch: Plugin de Ingestão de Anexos
Elasticsearch: Plugin de Ingestão de Anexos
Como extrair dados de ficheiros PPT, XLS e PDF para Elasticsearch
👋 Bem-vindo à documentação da Stackhero!
A Stackhero oferece uma solução Elasticsearch cloud pronta a usar que proporciona uma série de benefícios, incluindo:
- Desempenho ótimo e segurança robusta alimentados por uma VM privada e dedicada.
- Nome de domínio personalizável seguro com suporte de encriptação HTTPS.
Poupe tempo e simplifique a sua vida: são necessários apenas 5 minutos para experimentar a solução de Elasticsearch cloud hosting da Stackhero!
O plugin de Ingestão de Anexos analisa e extrai metadados e texto de vários formatos de ficheiros, incluindo apresentações PowerPoint, documentos Excel e PDFs. Utiliza o Apache Tika, uma poderosa biblioteca de extração de texto. Para uma lista completa dos formatos suportados, por favor visite o site do Tika.
Este guia irá ajudá-lo a começar com o plugin.
Adicionar o plugin ao Elasticsearch
Primeiro, ative o plugin na sua configuração do Stackhero Elasticsearch:
- Vá para a secção Elasticsearch no seu painel de controlo Stackhero.
- Selecione o plugin
ingest-attachmentdas opções disponíveis.
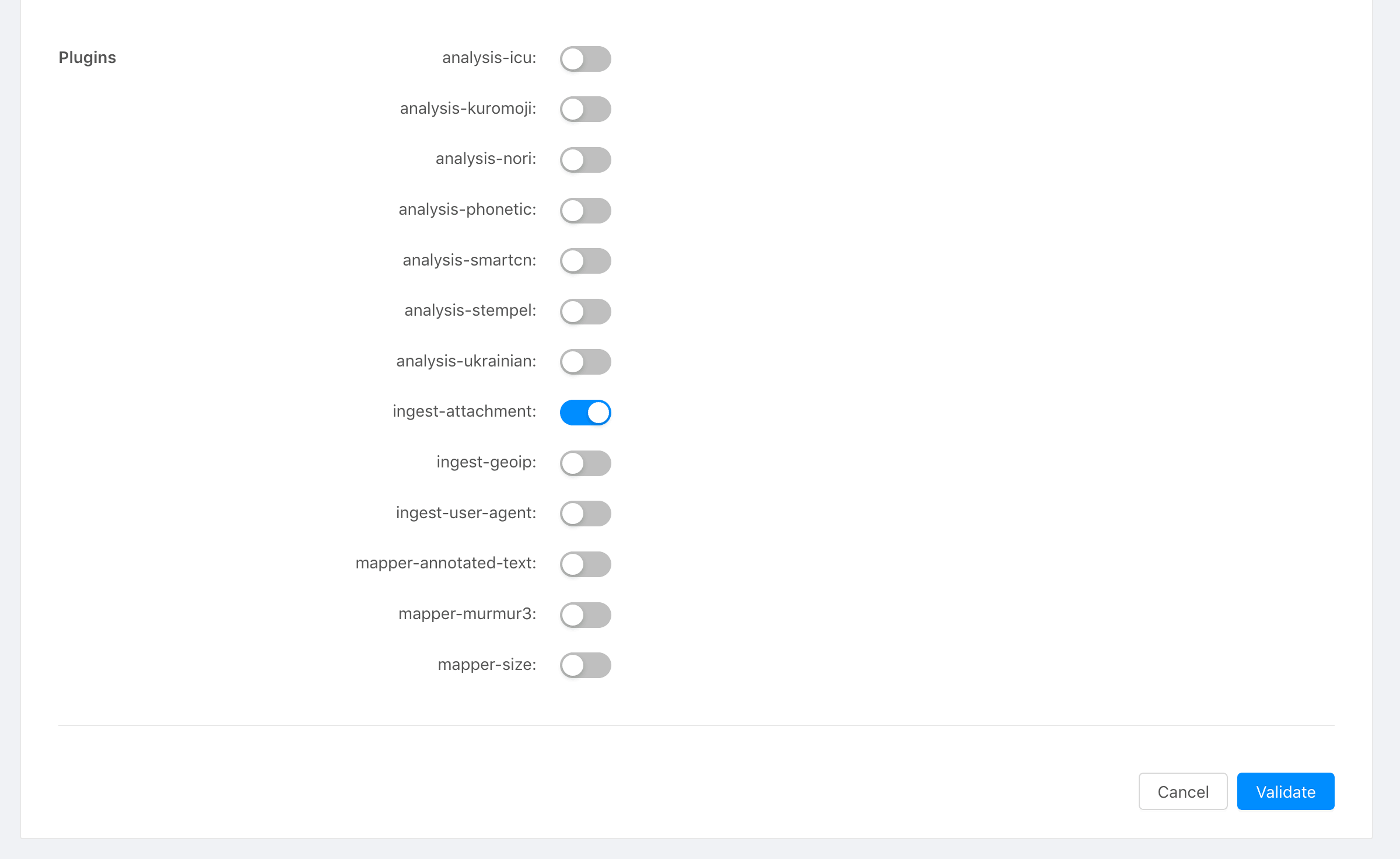 Painel de controlo Stackhero
Painel de controlo Stackhero
Declarar o pipeline de anexos
Em seguida, declare o pipeline de anexos no Elasticsearch. Neste exemplo, o conteúdo que deseja extrair está armazenado no campo data:
PUT _ingest/pipeline/attachment
{
"description": "Extrair informações de anexos",
"processors": [
{
"attachment": {
"field": "data"
}
}
]
}
Recomendamos usar as "Ferramentas de Desenvolvimento" no Kibana para uma execução simples por copiar/colar deste comando.
 Ferramentas de desenvolvimento Kibana
Ferramentas de desenvolvimento Kibana
Adicionar um documento com um anexo
Agora pode indexar um documento que contém um anexo. O documento deve incluir um campo data que contém o conteúdo do ficheiro codificado em Base64. Neste exemplo, o documento é um ficheiro RTF contendo a frase "This is the content of an RTF file":
PUT my_index/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ=="
}
Recuperar o documento com o conteúdo do anexo
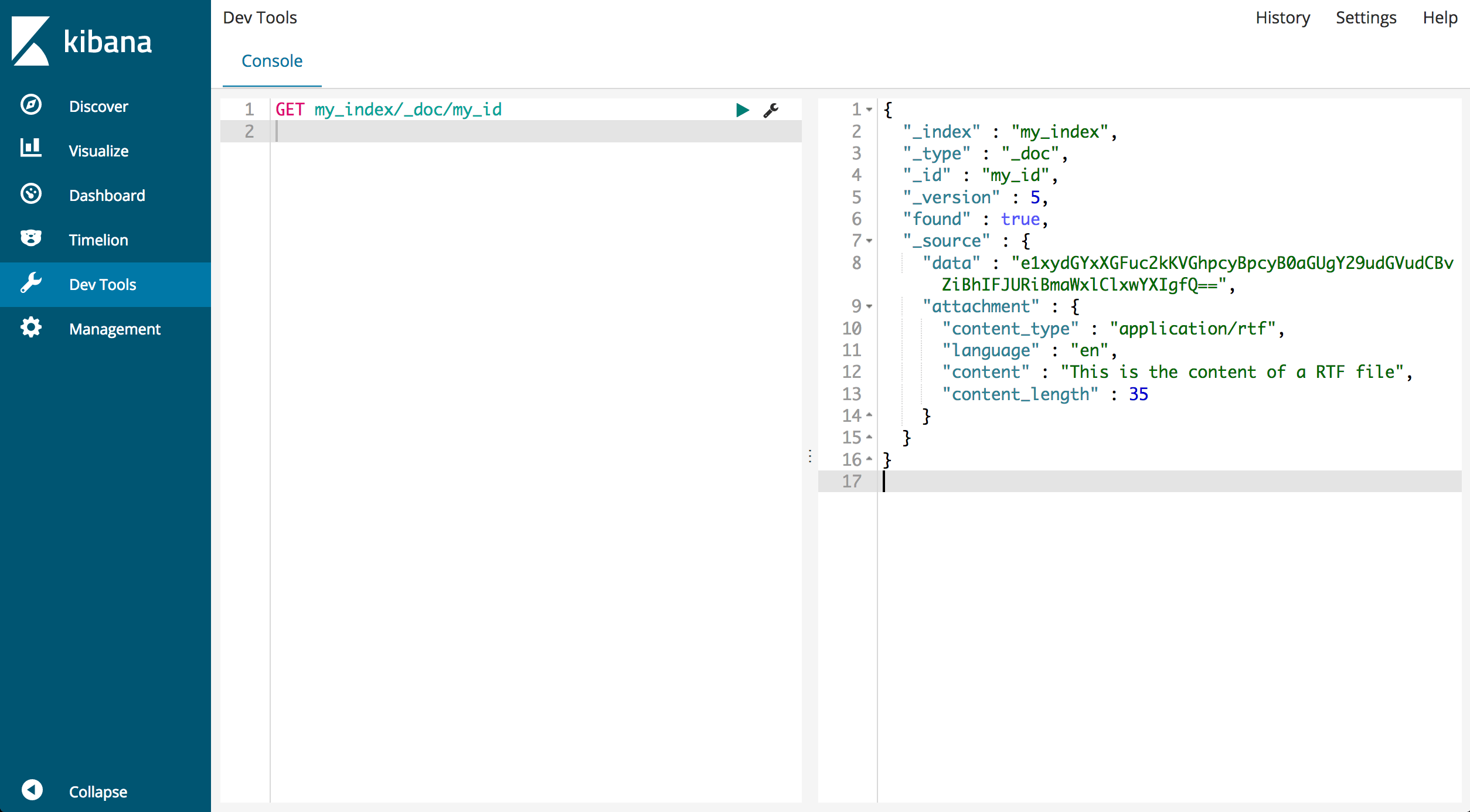
Para visualizar o documento processado, recupere-o usando o seu ID:
GET my_index/_doc/my_id
A resposta deverá ser semelhante ao seguinte:
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "my_id",
"_version" : 1,
"found" : true,
"_source" : {
"data" : "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ==",
"attachment" : {
"content_type" : "application/rtf",
"language" : "en",
"content" : "This is the content of a RTF file",
"content_length" : 35
}
}
}
Note que o campo _source agora inclui tanto os dados originais em Base64 como os detalhes do anexo extraído, como o tipo de ficheiro e o conteúdo.
Conclusão
O plugin de Ingestão de Anexos é uma ferramenta poderosa e intuitiva para extrair conteúdo e metadados de vários formatos de ficheiros. Integra-se diretamente com o Elasticsearch para uma ingestão de dados sem problemas. Para mais informações, por favor consulte a documentação oficial.