 Prometheus: Įspėjimai
Prometheus: Įspėjimai
Kaip veikia Prometheus įspėjimai ir kaip juos konfigūruoti
👋 Sveiki atvykę į Stackhero dokumentaciją!
Stackhero siūlo paruoštą naudoti Prometheus cloud sprendimą, kuris suteikia daugybę privalumų, įskaitant:
- Įtrauktas
Alert Manager, skirtas siųsti įspėjimus įSlack,Mattermost,PagerDutyir kt.- Skirtas el. pašto serveris, skirtas siųsti neribotus el. pašto įspėjimus.
BlackboxskirtasHTTP,ICMP,TCPir kitų protokolų tikrinimui.- Lengvas konfigūravimas su internetiniu konfigūracijos failų redaktoriumi.
- Paprasti atnaujinimai vienu paspaudimu.
- Optimali veikla ir tvirta sauga, užtikrinama privačios ir dedikuotos VM.
Taupykite laiką ir supaprastinkite savo gyvenimą: tereikia 5 minučių, kad išbandytumėte Stackhero Prometheus cloud hosting sprendimą!
Įvadas į Prometheus įspėjimus
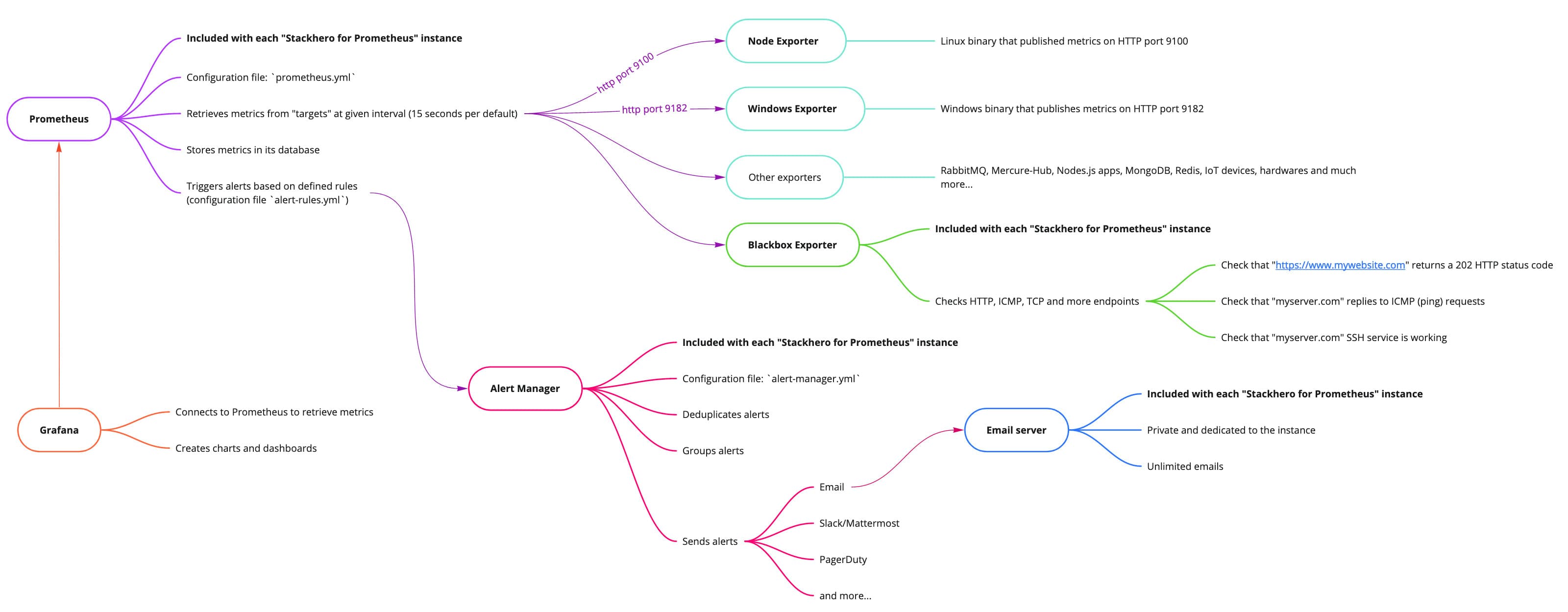
Prometheus gali analizuoti jūsų metrikas ir sukelti įspėjimus pagal jūsų nustatytas taisykles. Naudojant Stackhero for Prometheus, įspėjimai apdorojami dviem etapais. Pirma, įvertinamos Prometheus įspėjimų taisyklės, o tada perima Alert Manager.
Viskas yra iš anksto įdiegta ir sukonfigūruota su Stackhero for Prometheus, todėl jums tereikia atlikti minimalią konfigūraciją, pavyzdžiui, pridėti savo el. pašto adresą, kad pradėtumėte gauti įspėjimus.
 Didelis Stackhero for Prometheus vaizdas
Didelis Stackhero for Prometheus vaizdas
Įvadas į Prometheus įspėjimų taisykles
Kai Prometheus gauna metrikas, jis jas įvertina pagal taisykles, nurodytas rules-alert.yml faile. Šios įspėjimų taisyklės apibrėžia slenksčius ir laiko langus, kada sukelti įspėjimus pagal surinktas metrikas.
Pavyzdžiui, įspėjimas gali būti sukeltas, jei disko naudojimas viršija 80%. Be to, taisyklės gali būti nustatytos prognozuoti būsimas sąlygas ir siųsti įspėjimą, jei prognozuojama, kad disko vieta bus visiškai užpildyta per artimiausias 24 valandas.
Kitas dažnas naudojimo atvejis yra neįprasto elgesio aptikimas. Pavyzdžiui, jei staiga padidėja tinklo pralaidumo naudojimas, gali būti sukeltas įspėjimas, padedantis aptikti galimas paskirstytas paslaugų atsisakymo (DDoS) atakas ar duomenų ištraukimo bandymus.
Prometheus įspėjimų taisyklės yra tiesiogiai įtrauktos į Prometheus serverį.
Įvadas į Alert Manager
Alert Manager gauna įspėjimus, kuriuos sukėlė Prometheus įspėjimų taisyklės. Jis deduplikuoja įspėjimus, juos grupuoja ir tada perduoda per įvairius pranešimų kanalus, tokius kaip el. paštas, Slack, Mattermost, PagerDuty ir kt. Jo konfigūracijos failas yra alert-manager.yml.
Pavyzdžiui, jei įvyksta serverio sulėtėjimas, Prometheus įspėjimų taisyklės gali sukelti atskirus įspėjimus dėl padidėjusios apkrovos ir CPU naudojimo. Alert Manager gauna šiuos įspėjimus, juos grupuoja, nes jie susiję su tuo pačiu serveriu, ir siunčia vieną sujungtą pranešimą tinkamam gavėjui ar komandai pagal jūsų konfigūraciją.
Jei sulėtėjimas tęsiasi, Prometheus toliau siųs įspėjimus, bet Alert Manager slopins pasikartojančius pranešimus tam tikrą laikotarpį, kad išvengtų jūsų komandos užtvindymo pertekliniais įspėjimais.
Taip pat galite nutildyti arba visiškai slopinti įspėjimus, jei reikia. Kai pagrindinė problema išsprendžiama, siunčiamas atkūrimo pranešimas, kad praneštų jūsų komandoms.
Šis pavyzdys iliustruoja bendrą scenarijų, tačiau galite visiškai pritaikyti nustatymus pagal savo specifinius reikalavimus.
įspėjimas
Alert Managernėra įtrauktas pagal numatymą su Prometheus. Kad sutaupytume jūsų laiką ir supaprastintume procesą, mes integravome ir sukonfigūravomeAlert Managerį Stackhero for Prometheus, kad galėtumėte siųsti įspėjimus vos per kelias minutes, su minimaliomis pastangomis.
Prometheus įspėjimų taisyklių konfigūravimas
Galite koreguoti Prometheus įspėjimų taisykles redaguodami rules-alert.yml failą. Norėdami tai padaryti, pasiekite savo Stackhero prietaisų skydelį, pasirinkite savo Prometheus paslaugą ir spustelėkite "Prometheus įspėjimų taisyklių konfigūracija".
Jau pridėjome keletą numatytųjų įspėjimų taisyklių jūsų Stackhero for Prometheus instancijai, todėl paprastai nereikės keisti rules-alert.yml failo, nebent reikalinga pritaikymas.
Žemiau pateikiamas įspėjimo pavyzdys, kuris sukeliamas, jei disko naudojimas viršija 90%:
- alert: "HostOutOfDiskSpace"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)"
value: "{{ $value }}"
Čia yra kitas pavyzdys, kuris prognozuoja galimą disko vietos užsipildymą per artimiausias 24 valandas:
- alert: "HostDiskWillFillIn24Hours"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host disk will fill in 24 hours (instance {{ $labels.instance }})"
description: "Filesystem is predicted to run out of space within the next 24 hours at the current write rate"
value: "{{ $value }}"
Daugiau papildomų įspėjimų taisyklių pavyzdžių galite rasti Awesome Prometheus Alerts svetainėje.
Alert Manager konfigūravimas
Norėdami konfigūruoti Alert Manager, redaguokite alert-manager.yml failą. Savo Stackhero prietaisų skydelyje pasirinkite savo Prometheus paslaugą, tada spustelėkite "Alert Manager konfigūracija".
Žemiau pateikiame pagrindus. Daugiau informacijos rasite oficialioje dokumentacijoje.
Alert Manager konfigūravimas: gavėjai
Pirmas žingsnis yra konfigūruoti receivers. Kiekvienas receiver yra pranešimų integracijų rinkinys (pvz., el. paštas, Slack ir kt.), identifikuojamas unikaliu name.
Pavyzdžiui, galite sukurti gavėją pavadinimu "critical_alert" pranešimams, kuriuos sukelia kritinės svarbos įspėjimai. Arba galite sukurti gavėją, pavyzdžiui, "devops_team", kad nukreiptumėte įspėjimus į savo DevOps komandą.
Nustatant
receiverpavadinimą "critical_alert" vien tik nebus siunčiami įspėjimai. Asociacija tarp įspėjimų ir gavėjo atliekamarouteskonfigūracijoje, aprašytoje žemiau.
Kai gavėjas yra apibrėžtas, turėsite nustatyti atitinkamas pranešimų integracijas. Tai gali apimti el. laiškus, Slack/Mattermost pranešimus, PagerDuty, Opsgenie, Webhook ir kt.
Žemiau pateikiamas receiver pavyzdys pavadinimu "critical_alert", kuris siunčia el. laišką dviem vartotojams ir Slack pranešimą į #alerts kanalą:
receivers:
- name: "critical_alert"
# Siųsti kritinius įspėjimus el. paštu
email_configs:
- send_resolved: true
to: "user@mycompany.com"
# Siųsti kritinius įspėjimus į Slack arba Mattermost
slack_configs:
- send_resolved: true
api_url: "<your Slack or Mattermost API URL>"
channel: "#alerts"
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"
Galite apibrėžti kelis gavėjus, kad tvarkytumėte skirtingų tipų įspėjimus. Pavyzdžiui, galite turėti vieną kritiniams įspėjimams, kitą klaidų įspėjimams ir dar vieną kitų tipų įspėjimams.
Stackhero for Prometheus instancijos apima specialų ir privatų el. pašto serverį, kuris leidžia siųsti neribotą skaičių el. pašto įspėjimų be papildomų išlaidų.
Alert Manager konfigūravimas: maršrutai
Po to, kai sukonfigūruojate savo gavėjus, turite nustatyti routes. Maršrutai nurodo Alert Manager, kaip tvarkyti gaunamus įspėjimus iš Prometheus ir kur juos siųsti (paprastai į vieną iš jūsų iš anksto sukonfigūruotų gavėjų).
Žemiau pateikiamas pagrindinis pavyzdys, kuris nukreipia įspėjimus su "critical" svarba į gavėją pavadinimu "critical_alert":
route:
routes:
- match:
severity: "critical"
receiver: "critical_alert"
Mes iš anksto sukonfigūravome kai kuriuos maršrutus
alert-manager.ymlfaile, pateiktame su jūsų Stackhero for Prometheus instancija. Norėdami pradėti gauti įspėjimus, tiesiog atnaujinkiteemail_configsir/arbaslack_configsskyrius su savo pranešimų detalėmis.