 Elasticsearch: Plugin d'ingestion des pièces jointes
Elasticsearch: Plugin d'ingestion des pièces jointes
Comment extraire des données des fichiers PPT, XLS et PDF vers Elasticsearch
👋 Bienvenue sur la documentation de Stackhero !
Stackhero propose une solution Elasticsearch cloud prête à l'emploi offrant de nombreux avantages, notamment :
- Une performance optimale et une sécurité robuste grâce à une VM privée et dédiée.
- Un nom de domaine personnalisable sécurisé avec le support du chiffrement HTTPS.
Gagnez du temps et simplifiez-vous la vie : il suffit de 5 minutes pour essayer la solution Elasticsearch cloud hosting de Stackhero !
Le plugin Ingest Attachment analyse et extrait les métadonnées et le texte de divers formats de fichiers, y compris les présentations PowerPoint, les documents Excel et les PDFs. Il utilise Apache Tika, une bibliothèque d'extraction de texte puissante. Pour une liste complète des formats pris en charge, veuillez visiter le site de Tika.
Ce guide vous aidera à démarrer avec le plugin.
Ajouter le plugin à Elasticsearch
Tout d'abord, activez le plugin dans votre configuration Elasticsearch Stackhero :
- Allez dans la section Elasticsearch de votre tableau de bord Stackhero.
- Sélectionnez le plugin
ingest-attachmentparmi les options disponibles.
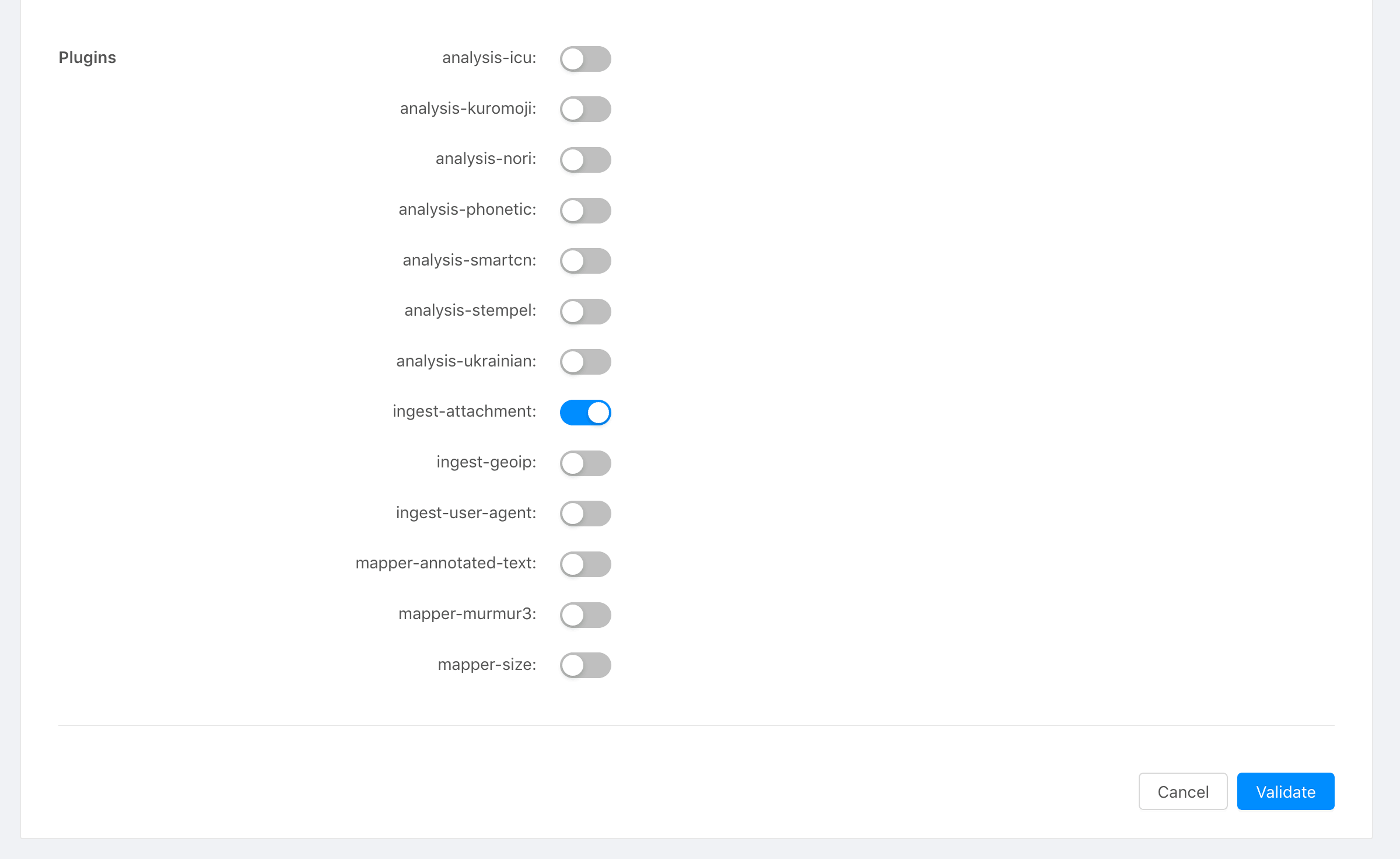 Tableau de bord Stackhero
Tableau de bord Stackhero
Déclarer le pipeline d'attachement
Ensuite, déclarez le pipeline d'attachement dans Elasticsearch. Dans cet exemple, le contenu que vous souhaitez extraire est stocké dans le champ data :
PUT _ingest/pipeline/attachment
{
"description": "Extraire les informations d'attachement",
"processors": [
{
"attachment": {
"field": "data"
}
}
]
}
Nous recommandons d'utiliser les "Dev Tools" dans Kibana pour une exécution simple par copier/coller de cette commande.
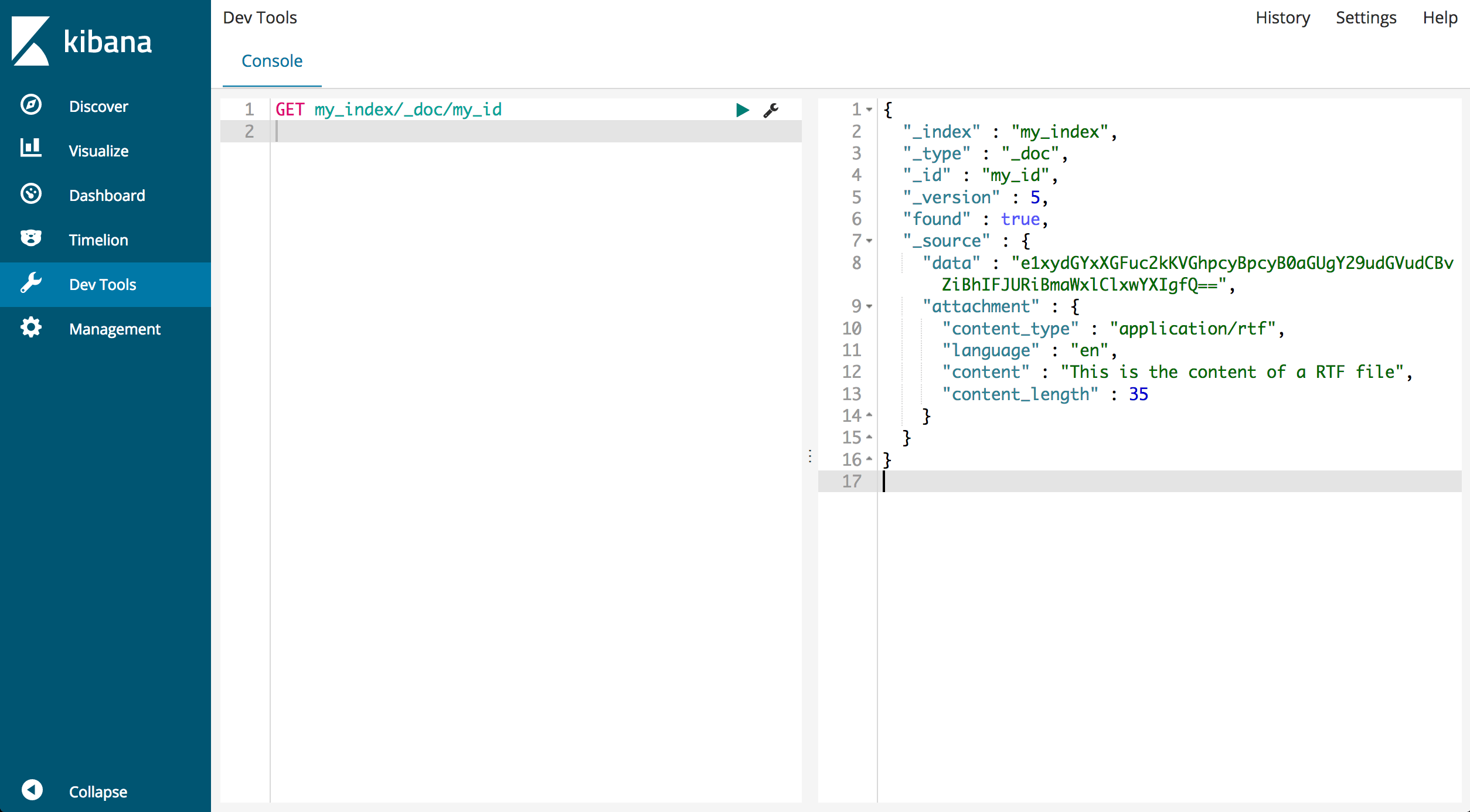 Outils de développement Kibana
Outils de développement Kibana
Ajouter un document avec une pièce jointe
Vous pouvez maintenant indexer un document contenant une pièce jointe. Le document doit inclure un champ data qui contient le contenu du fichier encodé en Base64. Dans cet exemple, le document est un fichier RTF contenant la phrase "This is the content of an RTF file" :
PUT my_index/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ=="
}
Récupérer le document avec le contenu de la pièce jointe
Pour voir le document traité, récupérez-le en utilisant son ID :
GET my_index/_doc/my_id
La réponse devrait ressembler à ce qui suit :
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "my_id",
"_version" : 1,
"found" : true,
"_source" : {
"data" : "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ==",
"attachment" : {
"content_type" : "application/rtf",
"language" : "en",
"content" : "This is the content of a RTF file",
"content_length" : 35
}
}
}
Notez que le champ _source inclut maintenant à la fois les données originales en Base64 et les détails de l'attachement extrait tels que le type de fichier et le contenu.
Conclusion
Le plugin Ingest Attachment est un outil puissant et intuitif pour extraire le contenu et les métadonnées de divers formats de fichiers. Il s'intègre directement avec Elasticsearch pour une ingestion de données fluide. Pour plus d'informations, veuillez vous référer à la documentation officielle.